Automotive ASICs and the functional safety standard ISO 26262
Over the past 20 years EnSilica has developed ASICs for several major automotive OEMs and tier-1 suppliers, based both here in the UK and in Europe and the US and these mixed-signal chips have controlled and enabled several functions from power management to ride comfort and, with all of these chips, a series of trade-offs are therefore balanced to achieve the right performance, cost, size, power etc.
Functional safety is obviously a core part of all of these and so, when looking for articles on ISO 26262 in, I recently re-stumbled upon an article written by our head of functional safety, Enrique Martinez, and after reading was glad we only deal with these technical trade-offs for vehicles, and not with the moral dilemmas.
In his article, published in EDN, he cites a 2018 Nature paper on the moral imperatives relating to decisions made by autonomous vehicles and how these vary region by region.
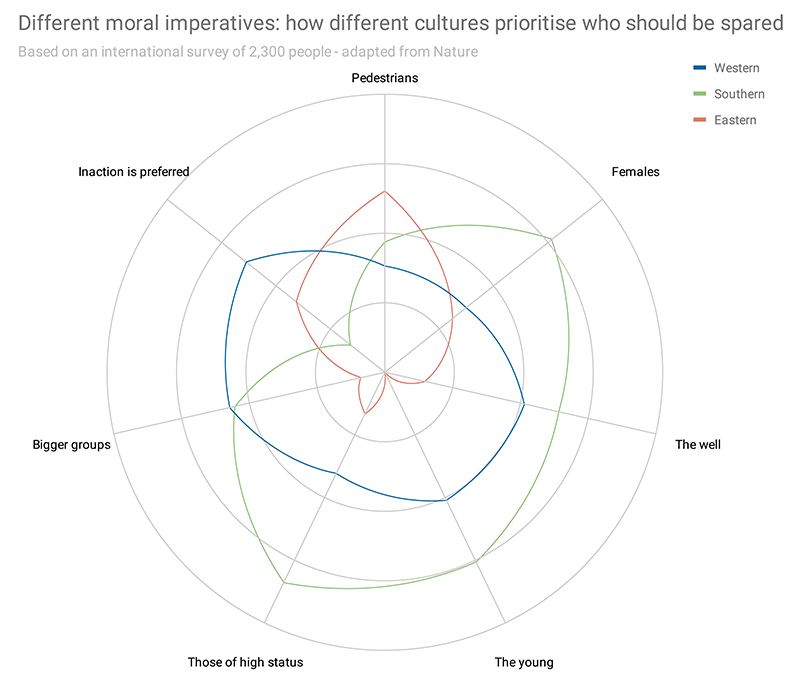
While the paper is, in effect, re-running the old runaway tramcar thought experiment, the differences in who gets protected are quite stark.
For example, Eastern cultures are more likely to protect the old, Southern cultures prefer inaction over purposeful selection, Western ones more likely to protect people of status over vulnerable users like pedestrians (thankfully this last one would be nigh-on impossible to code).
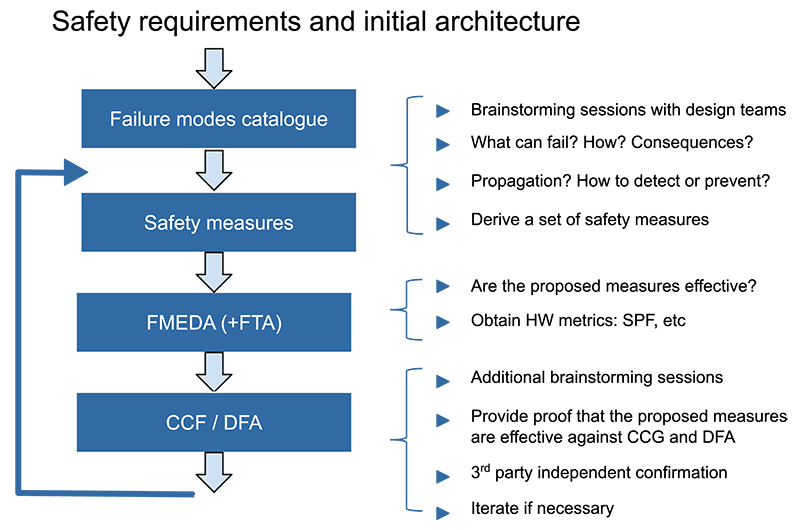
Considerations in developing safety critical SoCs
As mentioned, the article also looks at ISO 26262 and IEC 61508 and is well worth a read, and a summary can be found below:
As Enrique argues: Safety-critical projects require comprehensive safety analysis procedures. And a pivotal role in this process is played by the designer, establishing an understanding of potential malfunctions within a circuit or IP block and implementing mitigation strategies.
To make sure safety measures work, ISO 26262 also mandates that complex SoCs use specialised fault injection software tools to simulate common faults and ensure proper detection and/or correction mechanisms are in place.
Debugging embedded software is never easy, and challenges are further amplified when the code image is in the silicon itself (so traditional debugging tools become less effective /practical). The way around this is by running co-simulation models that encompass both hardware and software, and that give a comprehensive view of the system’s behaviour, even before you get your hands on the silicon itself.
The final key element in creating safety-critical systems is vendor verification, with any device used in applications governed by ISO 26262 needing fabs and subcontractors to demonstrate their ability to manufacture components to automotive safety standards. This means a communication flow with suppliers and customers that strictly adheres to safety plans and development interface agreements (DIA) is essential.
If you need more information than this short summary allows, you can read Enrique’s original article on EDN, here.